Zaman Serileri Analizi 4: Öngörü, Şimdigörü ve Tahmin
Zaman serileri
Author
Murat Öztürkmen
Published
January 1, 2022
1. Giriş
Sıklıkla birbirine karıştırılan iki kavram öngörü (forecasting) ve tahmin (prediction) kavramlarıdır. Öngörü ile birlikte
Tahmin (prediction), daha önce görülmemiş test verisi için sonuçların tahmin edilmesiyle ilgilidir. Bu amaçla, yeni \(x\) gözlemleri için tahminler yapabilen bir \(\hat{f}(x)\) tahmincisi ile sonuçlanan, eğitim veri kümesinde bir model eğitilir.
Öngörü (forecasting) problemleri, hem geçmiş verileri kullanan hem de gelecekteki olaylar hakkında konuşan tahmin problemlerinin bir alt kümesidir. Tahmin ve öngörü arasındaki tek fark, öngörüde zamansal boyutun açık bir şekilde dahil edilmesidir. Öngörü, zamana dayalı bir tahmindir, yani zaman serisi verileriyle uğraşırken daha uygundur. Öte yandan, tahminin yalnızca zamana dayalı olması gerekmez, hedef değişkeni etkileyen birden çok nedensel faktöre dayanabilir.
Şimdigörü (nowcasting) meteorolojide sıklıkla olmak üzere, ekonomide de kullanılan bir yaklaşımdır. Ekonomide şimdigörü, bir ekonomik göstergenin bugünün, çok yakın geleceğin ve çok yakın geçmişteki durumunun tahminidir. Meteorolojide şimdigörü, tipik olarak +0-6 saatlik bir ufka atıfta bulunan kısa süreli tahmindir. Genellikle en son gözlemlerin ekstrapolasyonu gibi sayısal yöntemleri kullanır ve bir tahminde bulunmak için Lagrange veya Eulerian kalıcılığını varsayar.
Öngörü genel olarak ikiye ayrılabilir: örneklem-içi öngörü ve örneklem-dișı öngörü. Tahmin sürecinde genellikle örneklem-içi performans dikkate alınır. Örneğin, en küçük kareler yönteminde kalıntı kareleri toplamı en küçük yapılarak en iyi örneklem-içi öngörü hesaplanır. Benzer șekilde olabilirlik fonksiyonu en yüksek yapıldığında en iyi örneklem-içi öngörüler olușturulmuș olur. Modellerin karșılaștırımasında bu tür örneklem-içi büyüklükler fazla yardımcı olmayabilir.
Örneklem-dıșı öngörüler rakip modellerin yarștırılmasında kullanılabilir. Öngörü denilince genellikle örneklem-dıșı öngörü anlașılır. Zaman serisinin elimizde \(T\) boyutlu sadece bir gerçekleșmesi olduğundan öngörülerin olușturulması için gözlemlerin bir kısmının tahmin için kalanı ise öngörü için kullanılır.
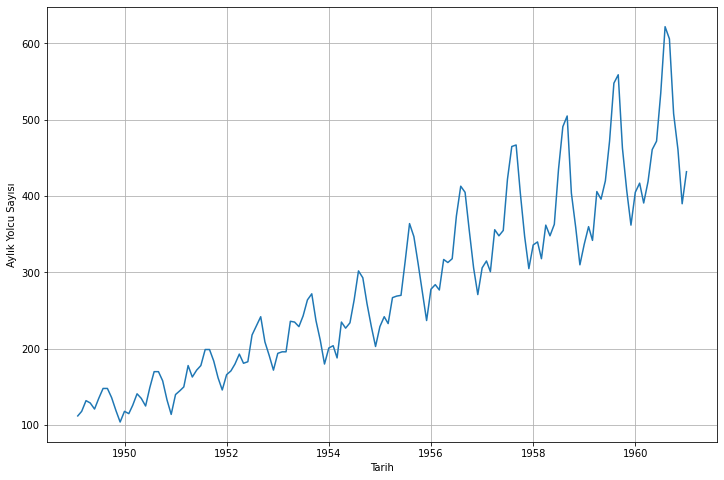
Bu yazı dizimizin bu kısmında, basit öngörü teknikleri ile başlayıp, ARIMA modelleri ile öngörü ve öngörülerin değerlendirilmesine bakacağız. Basitlik olması adına, meşhur Air Passengers verileri ile çalışacağız. Veri kümesine buradan erişebilirsiniz.
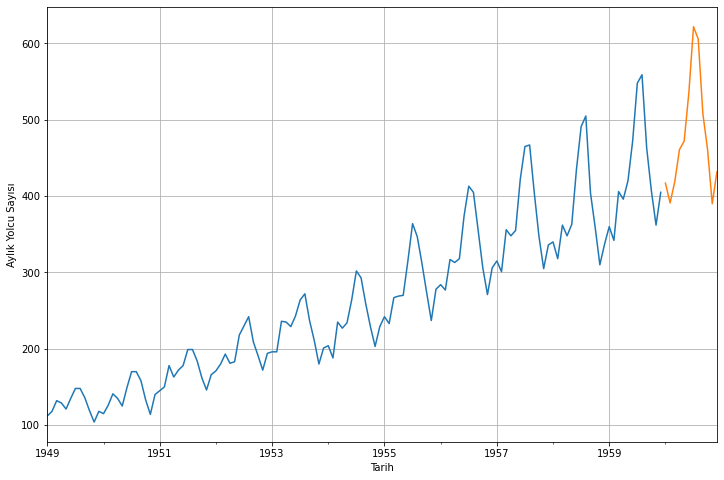
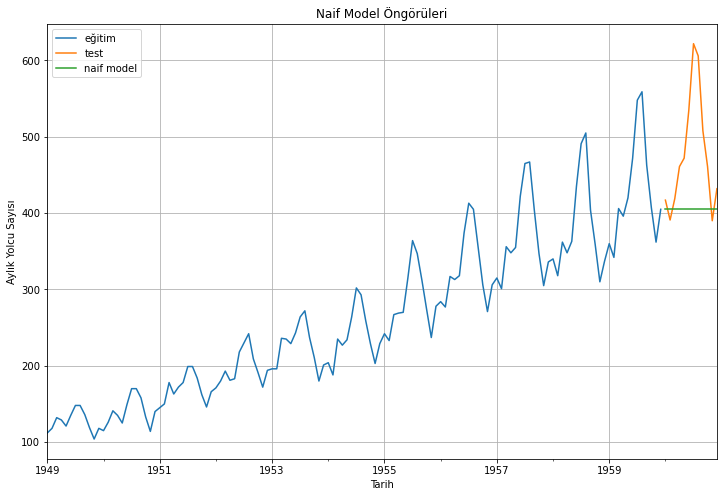
Tahminleri, eğitim verisini ve test verisini görselleştirelim:
eğitim_verisi['#Passengers'].plot(figsize=(12,8), label="eğitim")test_verisi['#Passengers'].plot(figsize=(12,8), label="test")naif_model_öngörüleri.plot(figsize=(12,8), label="naif model")plt.xlabel("Tarih")plt.ylabel("Aylık Yolcu Sayısı")plt.title("Naif Model Öngörüleri")plt.legend(loc='best')plt.grid()plt.show()
2.2. Basit Ortalama (Simple Average)
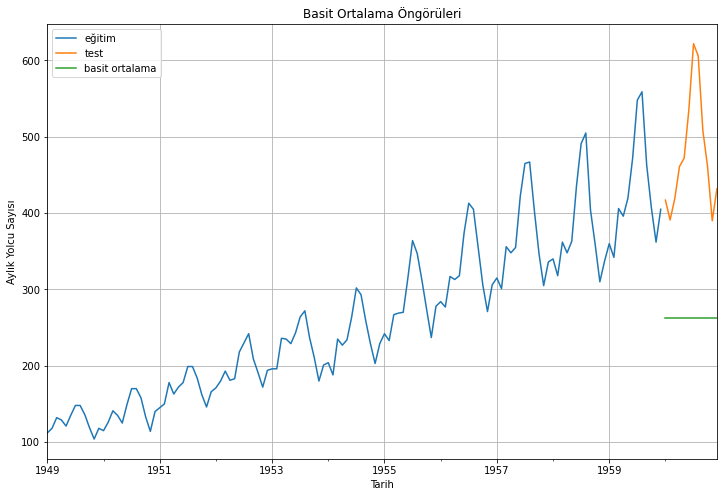
Çoğu zaman, zaman periyodu boyunca küçük bir farkla değişen, ancak her zaman periyodundaki ortalaması sabit kalan bir zaman serisi ile karşılaşılır. Böyle bir durumda, bir sonraki dönemin öngörüsünü, geçmiş dönemlerin ortalamasına yakın bir şekilde öngörebiliriz.
Önceden gözlemlenen tüm noktaların ortalamasına eşit beklenen değeri öngören bu tür öngörü yaklaşımına Basit Ortalama (Simple Average) tekniği denilir:
Tahminleri, eğitim verisini ve test verisini görselleştirelim:
eğitim_verisi['#Passengers'].plot(figsize=(12,8), label="eğitim")test_verisi['#Passengers'].plot(figsize=(12,8), label="test")basit_ortalama_öngörüleri["basit_ortalama"].plot(figsize=(12,8), label="basit ortalama")plt.xlabel("Tarih")plt.ylabel("Aylık Yolcu Sayısı")plt.title("Basit Ortalama Öngörüleri")plt.legend(loc='best')plt.grid()plt.show()
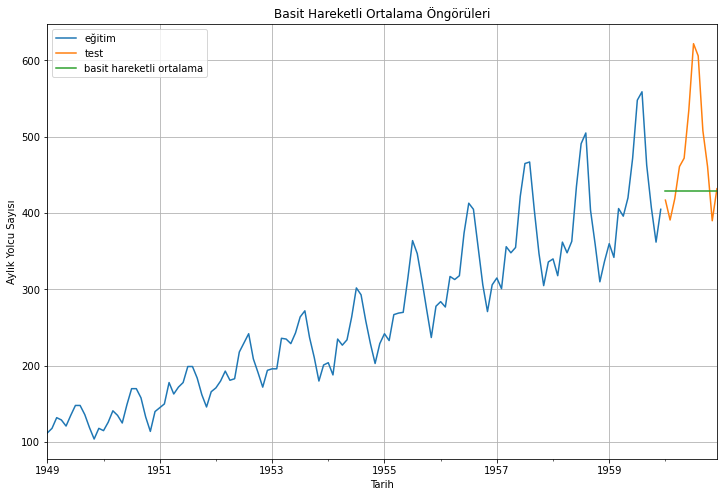
2.3. Basit Hareketli Ortalama (Simple Moving Average)
Serinin gözlemlerinin birkaç zaman önce keskin bir şekilde arttığı/azaldığı bir veri kümesi ile karşılaşabiliriz. Basit ortalama yöntemini kullanmak için önceki tüm verilerin ortalamasını kullanmalıyız, ancak önceki tüm verileri kullanmak, böyle bir durumda doğru olmaz.
İlk dönem gözlemlerinin kullanılması, bir sonraki dönem için öngörüleri büyük ölçüde etkileyecektir. Bu nedenle, basit ortalamanın üzerinde bir iyileştirme olarak, yalnızca son birkaç dönem için gözlemlerin ortalamasını alacağız. Buradaki temel düşünce, yalnızca son gözlemlerin önemli olduğudur. Ortalamayı hesaplamak için zaman aralığı penceresini kullanan bu tür öngörü yöntemine Hareketli Ortalama (moving average) yöntemi denir. Hareketli ortalamanın hesaplanması, bazen \(n\) boyutunda “kayan pencere (sliding window)” olarak adlandırılan yöntemi içerir.
Basit hareketli ortalama ile, önceki gözlemlerin sabit sonlu \(p\) adedinin ortalamasına dayalı olarak, serideki sonraki değerleri öngörebiliriz. Tüm \(i > p\) için:
Tahminleri, eğitim verisini ve test verisini görselleştirelim:
eğitim_verisi['#Passengers'].plot(figsize=(12,8), label="eğitim")test_verisi['#Passengers'].plot(figsize=(12,8), label="test")basit_hareketli_ortalama_öngörüleri["basit_hareketli_ortalama"].plot(figsize=(12,8), label="basit hareketli ortalama")plt.xlabel("Tarih")plt.ylabel("Aylık Yolcu Sayısı")plt.title("Basit Hareketli Ortalama Öngörüleri")plt.legend(loc='best')plt.grid()plt.show()
Hareketli ortalama yöntemine göre bir adım daha bir iyileştirme, ağırlıklı hareketli ortalama yöntemidir. Hareketli ortalama yönteminde, geçmiş \(n\) adet gözlemi eşit olarak tartıyoruz. Ancak geçmişteki \(n\) gözlemin her birinin, öngörüleri farklı bir şekilde etkilediği durumlarla karşılaşabiliriz. Geçmiş gözlemleri farklı şekilde tartan bu yaklaşıma Ağırlıklı Hareketli Ortalama (Weighted Moving Average) denilir.
Ağırlıklı hareketli ortalama, kayan pencere içindeki gözlemlere farklı ağırlıkların verildiği, genel olarak daha yeni noktaların daha önemli olduğu bir hareketli ortalamadır:
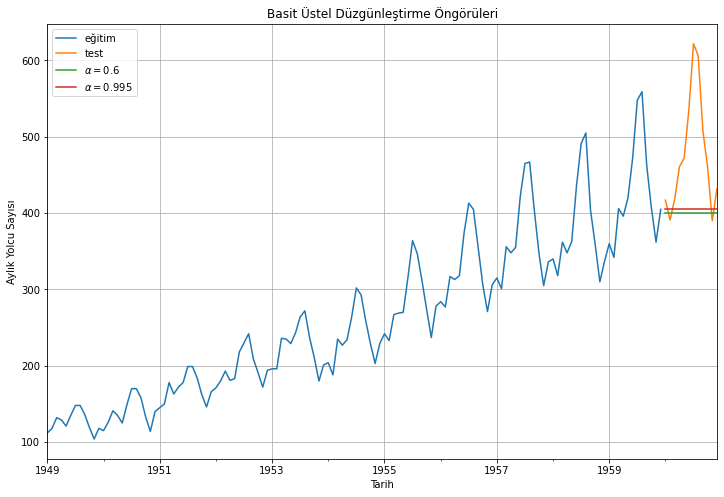
Gözlem noktalarını farklı şekilde tartarken tüm gözlemleri hesaba katan bu hareketli ortalama ve ağırlıklı hareketli ortalama yaklaşımları arasında bir şeye ihtiyacımız olur. Örneğin, uzak geçmişten gelen gözlemlere göre daha yakın tarihli gözlemlere daha büyük ağırlıklar vermek mantıklı olabilir. Bu prensibe göre çalışan yaklaşım, Basit Üstel Düzgünleştirme (Simple Exponential Smoothing) olarak adlandırılır. Öngörüler, ağırlıklı ortalamalar kullanılarak hesaplanır, burada gözlemler geçmişten geldikçe üstel olarak azalır, en küçük ağırlıklar en eski gözlemlerle ilişkilendirilir:
Basit üstel düzgünleştirme ile yolcu sayılarının öngörüsünü gerçekleştirelim. Burada \(\alpha\) parametresini iki şekilde belirleyeceğiz: ilkinde el ile, ikincisinde ise statsmodels çerçevesinin parametreyi ayarlamasını sağlayarak:
Tahminleri, eğitim verisini ve test verisini görselleştirelim:
eğitim_verisi['#Passengers'].plot(figsize=(12,8), label="eğitim")test_verisi['#Passengers'].plot(figsize=(12,8), label="test")basit_üstel_düzgünleştirme_öngörüleri["basit_üstel_düzgünleştirme1"].plot(figsize=(12,8), label=r"$\alpha=0.6$")basit_üstel_düzgünleştirme_öngörüleri["basit_üstel_düzgünleştirme2"].plot(figsize=(12,8), label=r"$\alpha=0.995$")plt.xlabel("Tarih")plt.ylabel("Aylık Yolcu Sayısı")plt.title("Basit Üstel Düzgünleştirme Öngörüleri")plt.legend(loc='best')plt.grid()plt.show()
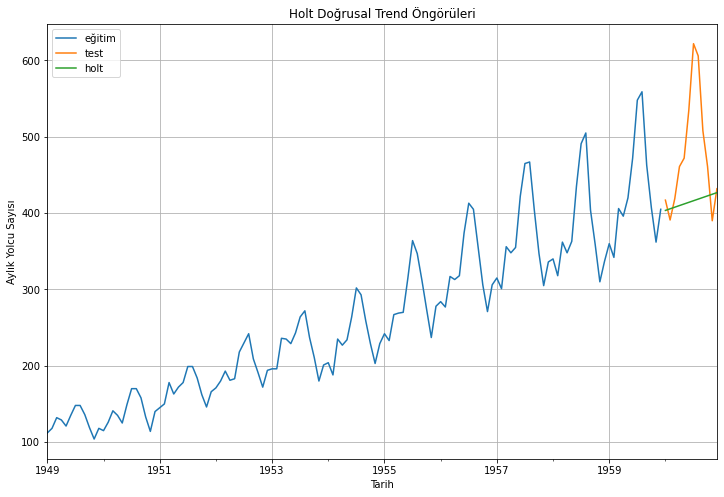
2.6. Holt Doğrusal Trend Yöntemi
Holt, trendi dikkate alarak, gelecek dönem öngörülerini gerçekleştirmek için basit üstel düzügünleştirme yaklaşımını gliştirir. Bu yaklaşım, hem seviyeye (serideki ortalama değer) hem de trende uygulanan üstel düzgünleştirmeden başka bir şey değildir. Bunu matematiksel gösterimle ifade etmek için şimdi üç denkleme ihtiyacımız var: biri seviye için, biri trend için ve biri de beklenen öngörüyü elde edecek şekilde için seviye ve trendi birleştirmek için \(ŷ\):
Tahminleri, eğitim verisini ve test verisini görselleştirelim:
eğitim_verisi['#Passengers'].plot(figsize=(12,8), label="eğitim")test_verisi['#Passengers'].plot(figsize=(12,8), label="test")holt_öngörüleri["holt"].plot(figsize=(12,8), label="holt")plt.xlabel("Tarih")plt.ylabel("Aylık Yolcu Sayısı")plt.title("Holt Doğrusal Trend Öngörüleri")plt.legend(loc='best')plt.grid()plt.show()
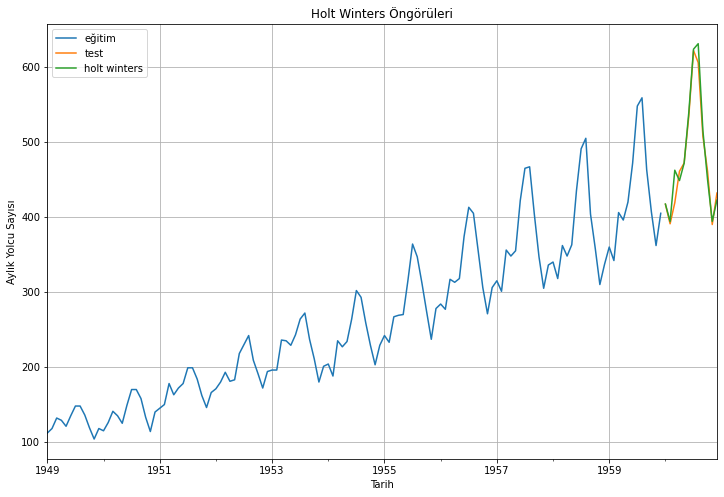
2.7. Holt-Winters Yöntemi
Yukarıda bahsedilen modeller, öngörüleri gerçekleştirirken gözlemlerin mevsimselliğini hesaba katmaz. Dolayısıyla, gelecekteki gözlemleri öngörmek için hem trendi hem de mevsimselliği hesaba katan bir yönteme ihtiyacımız var. Böyle bir senaryoda kullanabileceğimiz böyle bir algoritma Holt’un Winters yöntemidir. Üçlü üstel düzgünleştirmenin (triple exponential smoothing-Holt’s Winter) arkasında yatan teml fikir, seviye ve trende ek olarak mevsimsel bileşenlere üstel düzgünleştirme uygulamaktır.
Mevsimsellik faktörü nedeniyle Holt-Winters yöntemini kullanmak diğer modeller arasında en iyi seçenek olacaktır. Holt-Winters mevsimsel yöntemi, bir önörü denkleminden, ve biri \(\ell_{t}\) düzeyi için, biri trend \(b_{t}\) için ve diğeri α, β ve γ yumuşatma parametreleriyle birlikte \(s_{t}\) ile gösterilen mevsimsel bileşen için olmak üzere üç düzleştirme denkleminden oluşur.
Box ve Jenkins’in geliștirdiği \(\operatorname{ARIMA}(p, d, q)\) modelleme yaklașımının pratikteki amacı çoğunlukla öngörü olușturmaktır.
\(j\) dönem sonrası için öngörü olușturmak isteyen arastırmacının bilgi kümesinde \(t\) dönemi ve ön cesine ilișkin \(y_{t}\) değerlerinin yer aldığını vars ayalım Öng örü hata varyansını en küçük yapan öngörünün \(y_{t+j}\) ’nin koșullu beklentisi olduğu kolayca gösterilebilir. Bir bașka ifadeyle, olușturulacak öng örü așağıdaki gibi yazıabilir:
Gelecekte ne kadar uzağa öngörü yapılirsa yapilsın öngörü hatasının beklenen değeri sıfırdır. Ancak, öngörünün değișkenliği \(j\) ile birlikte artmaktadır. Genel durum için öngörü hatasının varyansı
olur 1 - dönem sonrası için öngörü varyansı \(\sigma^{2}\) iken 2 - dönem sonrası için öngörü varyansı \(\sigma^{2}\left(1+\phi^{2}\right)\) olmaktadır. Öngörü ufku arttıkça belirsizlik de artmaktadır. Limitte öngörü varyansının koșulsuz varyansa yaklașacağı açıktır:
\(\epsilon_{t}\) ’nin normal dağıldığı varsayımı altında olușturulan öngörüler için standart güven aralıkları hesaplanabilir.
Genel \(\operatorname{ARMA}(p, q)\) modelleri çerçevesinde olușturulan öngörüler de benzer yapıya sahiptir. Durağan modellerde \(y_{t+j}\) ’nin koșullu beklenen değeri \(j\) artarken ARMA sürecinin koșulsuz beklentisine yaklașmaktadır. Ayrıca öngörü ufku arttıkça öngörülerin kesinliği azalmaktadır. Pratikte yakın dönemlere ilișkin öngörü olușturulması tercih edilir.
ARIMA üzerinde bir geliştürme, Mevsimsel ARIMA (Seasonal ARIMA)’ dır. Holt-Winters yöntemi gibi gözlemlerin mevsimselliğini hesaba katar.
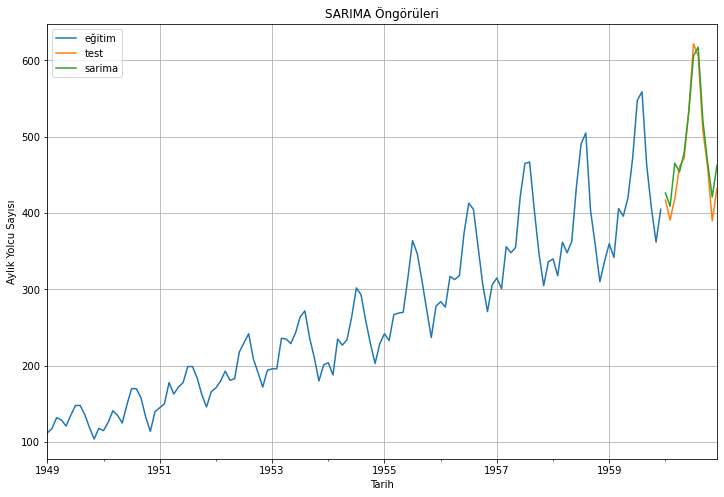
Mevrimsel ARIMA (SARIMAX) yöntemi ile yolcu sayılarının öngörüsünü gerçekleştirelim:
Tahminleri, eğitim verisini ve test verisini görselleştirelim:
eğitim_verisi['#Passengers'].plot(figsize=(12,8), label="eğitim")test_verisi['#Passengers'].plot(figsize=(12,8), label="test")sarima_öngörüleri["sarima"].plot(figsize=(12,8), label="sarima")plt.xlabel("Tarih")plt.ylabel("Aylık Yolcu Sayısı")plt.title("SARIMA Öngörüleri")plt.legend(loc='best')plt.grid()plt.show()
3.Öngörülerin Değerlendirilmesi
Box-Jenkins yaklașımında gözlemlenen serilerdeki dinamiği iyi yakalayan (white noise kalıntılı) ve fazla büyük olmayan modellerin tercih edilmesi önerilir. Uygulamada bu özellikleri sağlayan birden fazla rakip ARMA modellerine ulașılabilir. Bu modeller arasından hangisinin seçileceğine bilgi kriterleri \((\mathrm{AlC}, \mathrm{SBC}\), etc) yardımcı olabilir. Bunun yanı sıra, rakip modeller öngörü performansları açısından da karșıaștırılabilir.
1-dönem sonrası öngörüler için pratikte takip edilecek adımlar șöyle sıralanabilir:
Aday modelleri belirle: \(M_{1}, M_{2}\)
Tahminde kullanılacak örneklem hacmini \(\left(T_{1}\right)\) belirle (not: \(n=T-T_{1}\) dönem için 1 -dönem sonrasına öngörüler olușturulacaktır.)
\(i=1 \mathrm{icin} T_{1}+i-1\) gözlemden hareketle \(M_{1}\) ve \(M_{2}\) modellerini tahmin et, ve 1 dönem sonrası icin öngörüyü oluștur. Bunlara sırasıyla, \(\hat{y}_{T_{1}+1}^{(1)}\) ve \(\hat{y}_{T_{1}+1}^{(2)}\) ile gösterelim. Öngörü hataları her iki alternatif model için sırasıyla \[
e_{1}^{(1)}=y_{T_{1}+1}-\hat{y}_{T_{1}+1}^{(1)}, \quad e_{1}^{(2)}=y_{T_{1}+1}-\hat{y}_{T_{1}+1}^{(2)}
\]
\(i=2,3, \ldots, n\) icin 2 . ve 3. adımları tekrarla. Her tahminde örneklem boyutuna bir gözlemin eklendiğine dikkat edilmelidir. Bu hesapla maların sonucunda elimizde \(n\) boyutlu öngörü ve hata serileri olacaktır: \[
\begin{array}{ll}
\left\{\hat{y}_{t}^{(1)}\right\}_{t=T_{1}+1}^{T}, & \left\{e_{i}^{(1)}\right\}_{i=1}^{n} \\
\left\{\hat{y}_{t}^{(2)}\right\}_{t=T_{1}+1}^{T}, & \left\{e_{i}^{(2)}\right\}_{i=1}^{n}
\end{array}
\]
Öngörü hatalarından hareketle alternatif modellerin performanslarını karșılaștır.
Öngörü performanslarının karșıaștırıImasında çeșitli ölçütler ve testler kullanılmaktadır. Yaygın olarak kullanılan ölçütler șunlardır:
Hata Karelerinin Ortalamasının Karekökü (Root Mean Squared Error) \[
R M S E=\sqrt{\frac{1}{n} \sum_{i=1}^{n} e_{i}^{2}}
\]
Mutlak Hatanın Ortalaması (Mean Absolute Error): \[
M A E=\frac{1}{n} \sum_{i=1}^{n}\left|e_{i}\right|
\]
Kestirim Hatalarının Karelerinin Ortalaması (Mean Squared Prediction Error): \[
M S P E=\frac{1}{n} \sum_{i=1}^{n} e_{i}^{2}
\]
Bu formüllerde \(e_{i}\) öngörü hatasını göstermektedir.
\(e_{i}=(t+i)\) zamanında gözlenen değer- \((t+i)\) zama nında öngörülen değer
model performans
6 holt winters 15.809645
7 sarima 20.765954
2 basit hareketli_ortalama 88.473160
5 holt 95.413292
0 naif yöntem 102.976535
4 basit üstel düzgünleştirme2 103.124454
3 basit üstel düzgünleştirme1 106.127007
1 basit ortalama 226.265671
RMSE ölçütüne göre, en düşük hata Holt Winters yöntemi ile elde edilen öngörüler ile elde edilmiştir.
Modellerin değerlendirilmesinde başka istatistiksel ölçütler de kullanılabilir. Bunlardan bazıları F testi, Granger-Newbold testi, Diebold-Mariano testi ve Uzun Dönem Varyans testidir.
3.1.F Testi
Elimizde rakip iki model olduğunu düșünelim ve bunlara ait MSPE değerlerini sırasyla, \(M S P E_{1}\) ve \(M S P E_{2}\) ile gösterelim.
Öngörü performanslarının aynı olduğunu söyleyen boș hipotez altında MSPE değerlerinin oranı \((n, n)\) serbestlik derecesiyle \(F\) dağılımına uyar:
\[
\frac{M S P E_{1}}{M S P E_{2}} \sim F(n, n)
\]
Boș hipotezin reddedilmesi \(M S P E_{1}\) ’in \(M S P E_{2}\) ’den daha büyük olduğu anlamına gelir. Bu durumda daha kücük öngörü hata varyansına sahip olan ikinci model tercih edilir.
Ancak, bu testin geçerli olması için așağıdaki varsayımların sağlanması șarttır:
Öngörü hataları sıfır ortalama ile normal dağılıma uyar,
Farklı modellerden elde edilen öngörü hataları cari dönem itibariyle ilișkisizdir,
Öngörü hatalarında dizisel korelasyon yoktur.
Özellikle 2. ve 3. varsayımların sağlanmaması sonucu MSPE oranları F dağılımına uymaz ve test geçersiz olur. Literatürde çeșitli öngörü testleri önerilmiștir.
3.2.Granger-Newbold (GN) Testi
Cari dönem itibariyle ilișkili olmasına izin vermektedir ancak öngörü hatalarında otokorelasyon olmamalıdır. \(e_{1 i}\) ve \(e_{2 i}\) rakip iki modelden elde edilen öngörü hataları olmak üzere GN testi așağıdaki iki ya pay zaman serisine dayanır:
\[
\begin{array}{l}
z_{i}^{+}=e_{1 i}+e_{2 i}, \quad i=1,2, \ldots, n \\
z_{i}^{-}=e_{1 i}-e_{2 i}, \quad i=1,2, \ldots, n
\end{array}
\]
Öngörü hatalarının normal dağılması ve dizisel özilintinin olmaması varsayımları altında \(z_{i}^{+}\) ve \(z_{i}^{-}\) serilerinin ilișkisiz olması beklenir.
Populasyon korelasyon katsayısı \[
\rho=\mathrm{E}\left(z_{i}^{+} z_{i}^{-}\right)=\left(e_{1 i}^{2}-e_{2 i}^{2}\right)
\]
\(\rho=0\) ise öngörü performansları eșittir. \(\rho>0\) ise ilk modelin varyansı daha büyüktür \(\left(M S P E_{1}>M S P E_{2}\right) . \rho<0\) ise ikinci modelin varyansı daha büyüktür \(\left(M S P E_{1}<M S P E_{2}\right)\). \(H_{0}: \rho=0\) hipotezi altında GN test istatistiği
\[
G N=\frac{\hat{\rho}}{\sqrt{\left(1-\hat{\rho}^{2}\right) /(n-1)}} \sim t_{n-1}
\]
Burada \(\hat{\rho}\) örneklem korelasyon katsayısıdır. Pozitif ve anlamlı bir sonuc çıkarsa ikinci model tercih edilecektir ( \(M S P E_{1}\) daha büyük). Negatif ve anlamlı bir sonuç çıkarsa birinci model tercih edilecektir.
Testin anlamsız çıkması öngörü performanslarının eșdeğer olduğuna ișaret eder.
3.3.Diebold-Mariano (DM) Testi
\(\left\{e_{1 i}\right\}_{i=1}^{n}\) ve \(\left\{e_{2 i}\right\}_{i=1}^{n}\) rakip iki modelden elde edilen öngörü hataları olsun.
DM testi bu iki öngörü hatası serisinden hareketle hesaplanan loss fonksiyonlarını karșılaștırır. \(L_{i}^{j} j\) modelinden elde edilen loss fonksiyonu olmak üzere DM test istatistigi öngörü performansının eșit olup olmadığını test eder:
DM test istatistiğinin hesa planması oldukça basittir. Loss fonksiyonları arasındaki farkın standardize edilmesine dayanır. Öngörü hatalarında otokorelasyon olduğundan DM uzun dönem varyans tahmin edicisinin kulla nılmasını önermișlerdir. DM test istatistiği șu șekilde hesaplanır:
\[
D M=\frac{\bar{d}}{\sqrt{L \hat{R} V(\bar{d}) /(n-1)}}
\]
Burada \(L \hat{R} V\) uzun dönem varyansının (long run variance) bi tahminidir.
3.4.Uzun Dönem Varyans (Long Run Variance-LRV)
\(y_{t}\) durağan ve ergodik bir zaman serisi ise gösterilebilir ki
\[
\sqrt{T}(\bar{y}-\mu) \stackrel{d}{\longrightarrow} N\left(0, \sum_{j=-\infty}^{\infty} \gamma_{j}\right)
\] ya da
Uzun dönem varyansı ise \[
L R V_{y}=T \cdot \frac{1}{T} \sum_{j=-\infty}^{\infty} \gamma_{j}=\sum_{j=-\infty}^{\infty} \gamma_{j}
\]
\(\gamma_{-j}=\gamma_{j}\) olduğundan așaıdaki gibi yazılabilir:
\[
L R V_{y}=\gamma_{0}+2 \sum_{j=1}^{\infty} \gamma_{j}
\]
\(L R V\) ’nin tahmininde parametrik ya da parametrik olmayan yöntemler kullanılabilir. Serideki otokorelasyonun yapısını temsil edebilen yeterince uz un gecikmeye sahip bir \(\mathrm{AR}(\mathrm{p})\) modeli tahmin edilerek așağıdaki gibi hesaplanabilir.
\[
L \hat{R} V_{y}=\frac{\hat{\sigma}^{2}}{\left(1-\hat{\phi}_{1}-\hat{\phi}_{2}-\ldots-\hat{\phi}_{p}\right)^{2}}
\]
Burada \(\hat{\phi}_{j}\) AR katsay ılarının tahminidir. Alternatif bir parametrik olmayan tahmin edici Newey ve West (1987) tarafından önerilmiștir:
\[
L \hat{R} V_{y}=\hat{\gamma}_{0}+2 \sum_{j=1}^{q} w_{j} \hat{\gamma}_{j}
\]
\(w_{j}\) otokovaryansların ağırlıklarını, \(q\) ise pencere aralığını temsil etmektedir. Newey-West Bartlett ağırlıklarını önermiștir: